I'm diving deep into the world of data-intensive applications so you don't have to. Here's everything you need to know about reliability, detailed and demystified, from Martin Kleppmann's book, "Designing Data-Intensive Applications: Data Models and Query Languages"
What is a Data Model ? Why do we need it ?
A Data model is a blue print to the Databases, It describes how data is stored and organized, and how different pieces of data are related to each other. Imagine a Arranging Books on bookshelf; you have a structure or a schema while organizing it. All similar types of books go into particular sections: fiction books are in one section, non-fiction in another, and science fiction in yet another. You can arrange them systematically by genre, author, or title. So, your Bookshelf is like a database where you store books, i.e., data.
why we need Data Models .
Imagine you need to find a book and in Library or on the Internet there is no specific structure to store Books All books are out there stored Physically\Virtually at random. How hard will it be to find a specific book. For physical it will take days to skim through library containing 5000+ books and virtually u will need to traverse through N books at Time complexity of O(N) and Space Complexity of O(N). Similar is it with your Data.
We need Data Models for Two Important Things :
1)Data Storage: Store as much Data we need for working of our application. Any Application, Web services needs System that can store data.
2) Querying: Data Models makes it easier for us to retrieve the Information that has been stored properly within millisecond.
So, while storing data is important, it’s not enough on its own. Imagine if we stored all our books in one place without any sense of relationship. For instance, what if a Harry Potter book was stored next to The Monk Who Sold His Ferrari or an algebra textbook, or a Sanskrit book? Even though these books are stored properly, finding what we need would still take a lot of time because there’s no logical relationship or organization between them. This is why understanding data relationships becomes crucial.
Why do we need to know about what is relationship between Data ? .
To make sense of which Model we should use .
By defining relationships among the data, we can decide on the best data model to use, making our data storage not only organized but also efficient for querying. Relationships help us connect related data pieces, making it faster and easier to find specific information, just like having a well-organized library where books are grouped by genre or topic.
Different Types of Relationship between Data.
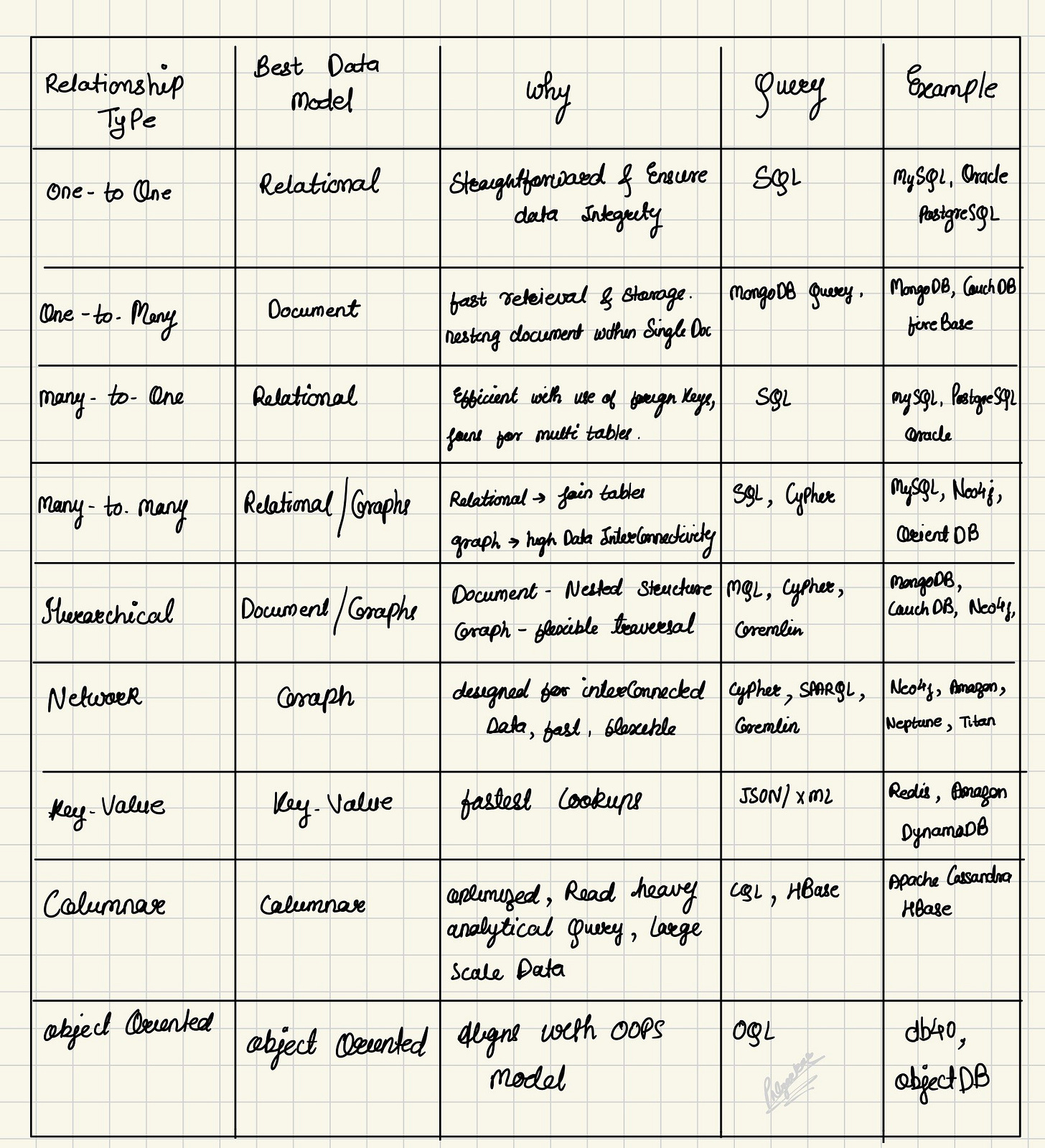
One-to-Many Relationship: This is like a parent-child connection, such as an author and their books. Knowing this relationship helps us design a data model that avoids redundancy and makes data retrieval straightforward.
Many-to-Many Relationship: This is like students and courses, where multiple students can enroll in multiple courses. Understanding this helps us use linking tables to manage these connections effectively, ensuring accurate data representation and easy querying.
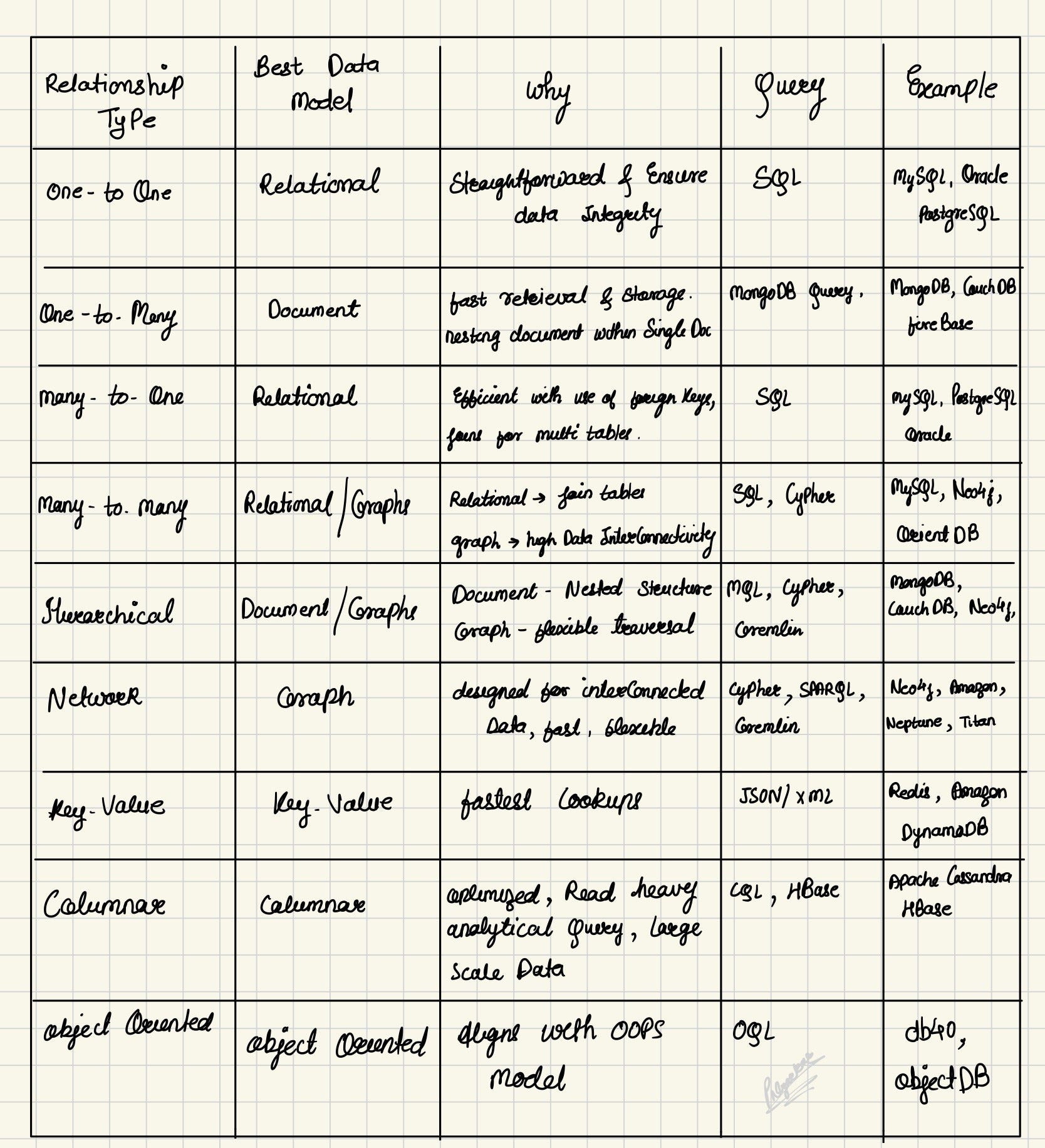
Main Types of Data Models, Their Uses, and Suitable Data Types:
1) Hierarchical Model
2) Document Model
3)Relational Model
4)Graphs
Lets Talk about different type of Data Model:
1. Hierarchical Model:
How is data Organized? : The Hierarchical Data Model is one of the earliest data models, where data is organized in a tree-like structure, with a single root and various levels of parent-child relationships.
In this model, each record (node) has a single parent but can have multiple children.(Limitation because of which network model was developed)
When to use?: We use this Model when we know our Database has Hierarchical Relationships.
Example: Best Example of model is IBM Information Management System (IMS). IMS was initially created to manage the massive amounts of data required for the Apollo space program.
Example on How Data is Organized in Hierarchical Data Model
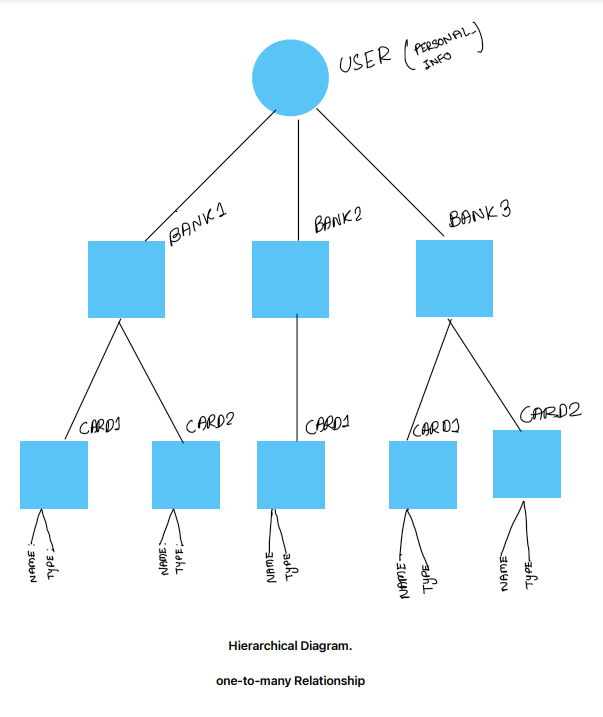
Imagine a person named John who has financial relationships with several banks. John might have different types of cards (like credit cards and debit cards) with each of these banks. To manage all of this information efficiently, we can organize it using a hierarchical model.
Root Level: User Financial Profile : This is the top level, representing the overall financial profile of the user. All other data is organized under this root.
Level 1: Banks: Child Nodes: Each bank where the user has accounts and cards. The user may have multiple banks.
Level 2: Cards: Under each bank, the user has multiple cards (e.g., debit cards, credit cards) directly associated with that bank. Child Nodes: Each card contains details like Card Type, Card Number etc.
2.Network Data Model:
CODASYL (Conference on Data Systems Languages) this standardization committee developed the network model to address limitations found in the earlier hierarchical model. It aimed to provide a more generalized data management approach.
what Limitation ?
Unlike the hierarchical model where each record can have only one parent, in the network model, a record can have multiple parent records. This allows for a more complex set of relationships between data items.How is Data Organised ? In the network model, records are linked through pointers These links are not foreign keys but are more direct, pointer-like connections stored on disk.
Access to records is achieved by navigating these pointers from one record to another, following predefined paths. To retrieve data, a programmer moves a cursor through the database, traversing these links according to the access paths defined.
When to Use? Use the network model when you need to manage complex relationship with multiple parents related to multiple children.
If a record is linked to multiple others, the programmer needs to manage these connections, making navigation complex.
Why did the Network & hierarchical Model Fail?
They are not memory-efficient and have poor time complexity due to the need to navigate an n-dimensional space for data traversal.
Modifications and updates to the database structure are complex and time-consuming because changes in data relationships require significant alterations in the memory layout and access paths.
Data retrieval is constrained by predefined access paths, limiting flexibility and increasing complexity in querying.
These models require manual navigation of complex link structures, making queries difficult to write, understand, and maintain.
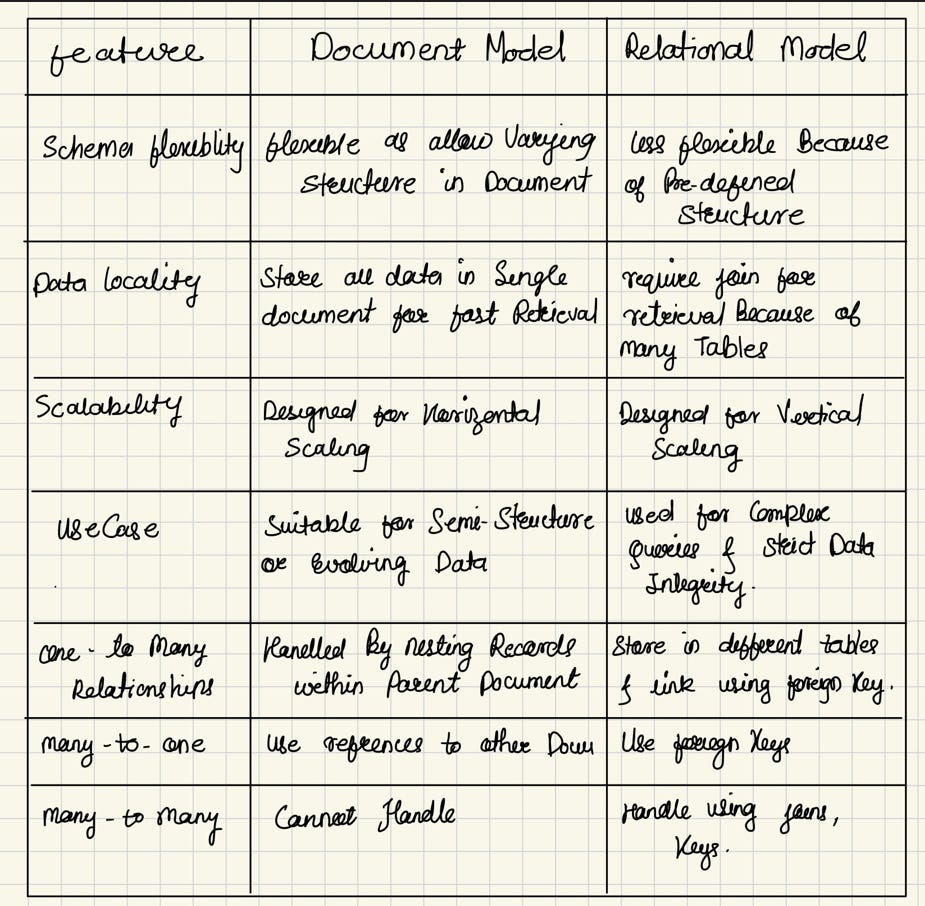
3.Relational Data Model :
How is data organized? : In the relational model, data is organized into tables, known as relations, which consist of rows (tuples) and columns (attributes).
Why is it Better than Earlier Models ? : The relational model makes managing data simple because of query optimizer you can easily read, add, or change data in tables based on specific rules or conditions, without needing to follow complex paths.
How does it improves flexibility and scalability ? by automatically using new indexes for queries. once a query optimizer is set up, all applications can use it to work faster and more efficiently.
when to use ? Use this model when you need to handle structured data with clear relationships between different entities. It is ideal when data integrity, consistency, and the ability to perform complex queries are important.
How does Relational Model handles data structure ?: Relational databases use a schema-on-write approach. This means a predefined schema is enforced when data is written, similar to static type checking. This approach ensures consistency and that all data conforms to a set structure, providing more control over data integrity.
Example: SQL-based relational databases like MySQL, Oracle, and PostgreSQL.
Relational Model Structure with Respect to earlier Card example :
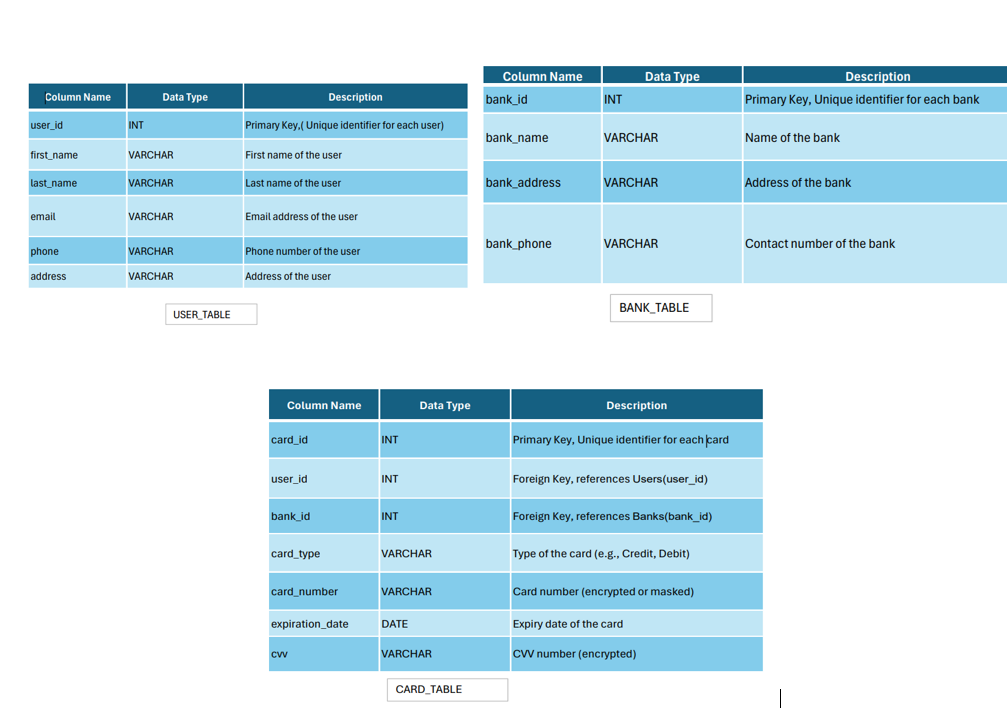
SQL Code to create Relational Database is linked here : SQL Table formation Code
4. Object-Oriented Data Model
How Data is Organized ? Data is organized into objects, which are instances of classes, similar to object-oriented programming.
Each object contains both data (attributes) and behaviors (methods).
Relationships between objects are established through the use of references and inheritance, allowing objects to be linked and interact with one another, reflecting real-world entities and their behaviors.When to use? Use the Object-Oriented Data Model when you need to represent complex data and behaviors with interacting objects and inheritance, making it ideal for simulations, multimedia systems, and applications with tightly coupled data and functionality.
Example: A typical example of the Object-Oriented Data Model is used in CAD (Computer-Aided Design) systems.
5.Document Model:
How data is organised?: The Document Model stores and organizes data in databases where each data item is a self-contained document.
These documents are represented using formats like JSON (JavaScript Object Notation), XML (Extensible Markup Language), BSON (Binary JSON), or similar structures.
Each document encapsulates data as key-value pairs and can represent complex nested structures.
When to use? Document databases handle nested records and one-to-many relationships by storing nested data directly within parent records, similar to the hierarchical model. Use the Document Model when you need to store semi-structured or unstructured data.
How does Document model handles data structure ? Document databases use a schema-on-read approach, where the data structure is interpreted when the data is read, similar to dynamic type checking in programming. This flexibility allows for varying structures in documents, accommodating changes in data format easily.
Examples: MongoDB: A widely-used NoSQL database that stores data in BSON (binary JSON) format, CouchDB: Uses JSON to store data and JavaScript as a query language, RethinkDB and Couchbase.
When should one choose schema-on-read over schema-on-write, and vice versa?
The choice between schema-on-read and schema-on-write depends on the specific needs of the application.
Schema-on-read offers flexibility, especially when the data structure may vary or change frequently, making it ideal for applications with evolving data requirements. Schema-on-write provides consistency and is suitable for applications that require strict data integrity and a stable data structure.
Can Document Data Model can be used as Relational and vice versa ?.
most relational databases have supported XML, and more recently, they have added support for JSON, enabling document-like functionality. On the other hand, document databases such as RethinkDB have incorporated relational-like joins, and MongoDB drivers can perform client-side joins by automatically resolving database references.
Which Data Model Leads to Simpler Application Code?
The choice of a data model that leads to simpler application code largely depends on the nature of the data and how it is structured:
Document Model
Pros: Avoids data splitting; aligns well with JSON/API outputs.
Cons: Limited in handling deep or complex queries; no native support for joins.Relational Model
Pros: Strong integrity and security; excellent for complex queries involving joins.
Cons: Can become cumbersome with heavy many-to-many relationships unless well-indexed; more rigid schema.Graph Model
Pros: Highly flexible for modeling complex networks; intuitive for complex relationship queries.
Cons: Often requires more specialized knowledge and can be more computationally intensive for large datasets.
Conclusion:
1) There is no one-size-fits-all answer. The decision depends on the nature of the relationships between data items.
2) Use the document model if the data is document-like and primarily involves one-to-many relationships.
3)Use the relational model if the data includes many-to-many relationships or requires complex queries involving multiple tables.
4)Consider a graph model if the data is highly interconnected with complex relationships.
Which is best Database ?
A hybrid approach that combines relational and document models is a promising direction, as it provides the versatility needed to handle various data scenarios effectively.6.Graph Model:
How data is organized ?
Data in a graph model is organized into vertices (or nodes) and edges (or relationships). Vertices represent entities, and edges represent the relationships between these entities. This setup allows for direct representation of networks and systems in their natural form without the need for foreign keys or join tables.When to use graph model ?
The graph model is ideal when dealing with highly interconnected data or relationships that aren't naturally hierarchical.Examples ? Neo4j known for its powerful Cypher query language that allows complex navigational queries, ArangoDB, OrientDB, Titan used for multi-machine Cluster.
Types of Graphs:
1) Property Graph Model:
It allows vertices and edges to have properties in the form of key-value pairs This model is implemented by databases like Neo4j, Titan, and InfiniteGraph.
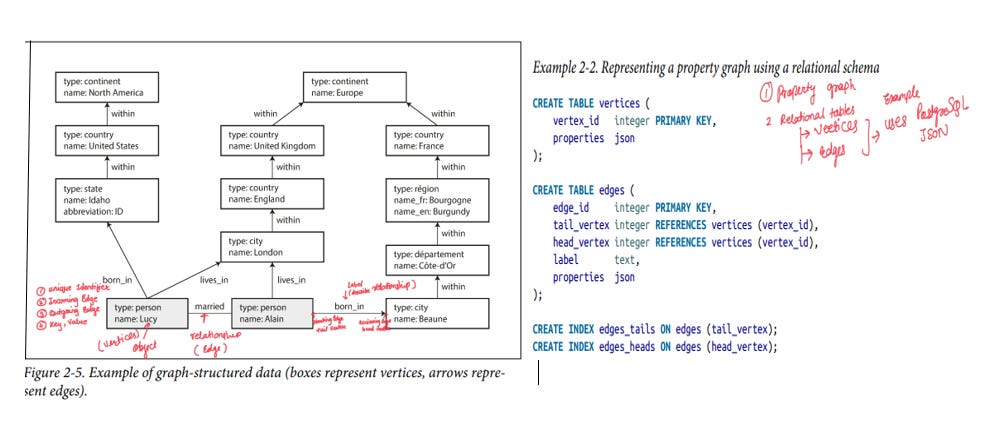
Vertices can connect freely without schema restrictions, allowing any type of entity to be linked with another.
It's easy to navigate the graph in both directions due to efficient indexing of incoming and outgoing edges.
Different relationship types are labeled, enabling the storage of diverse information while keeping the data model organized and clear.
The Cypher Query Language :
Cypher is a declarative query language for property graphs, created for the Neo4j graph database.
In the example above (Figure 2.5), a property graph is created to represent different locations and a person, along with their relationships. The Cypher query below shows how to define these nodes (representing entities like locations and people) and their relationships (illustrating how these entities are interconnected).
Cypher Query for figure 2.5 . This Cypher query finds people who were born in the United States and now live in Europe. It matches nodes labeled as person with BORN_IN relationships pointing to locations within the U.S. and LIVES_IN relationships pointing to locations within Europe. The *0.. wildcard allows it to traverse multiple levels of geographic hierarchy. The query returns the names of these people.
Can we formulate Same query in SQL ?.
Query : find people who were born in the United States and now live in Europe.


Query Structure for Relational Data Model in short :
a)Identify the "United States" vertex and create a set (in_usa) of all vertices connected by within edges.
b) Similarly, identify the "Europe" vertex and create a set (in_europe) of all vertices connected by within edges.
c) Find people born in locations within the in_usa set by following born_in edges.
d) Find people living in locations within the in_europe set by following lives_in edges.
e) Intersect the two sets to identify people who were born in the USA and now live in Europe.
2) Triple-Store Model:
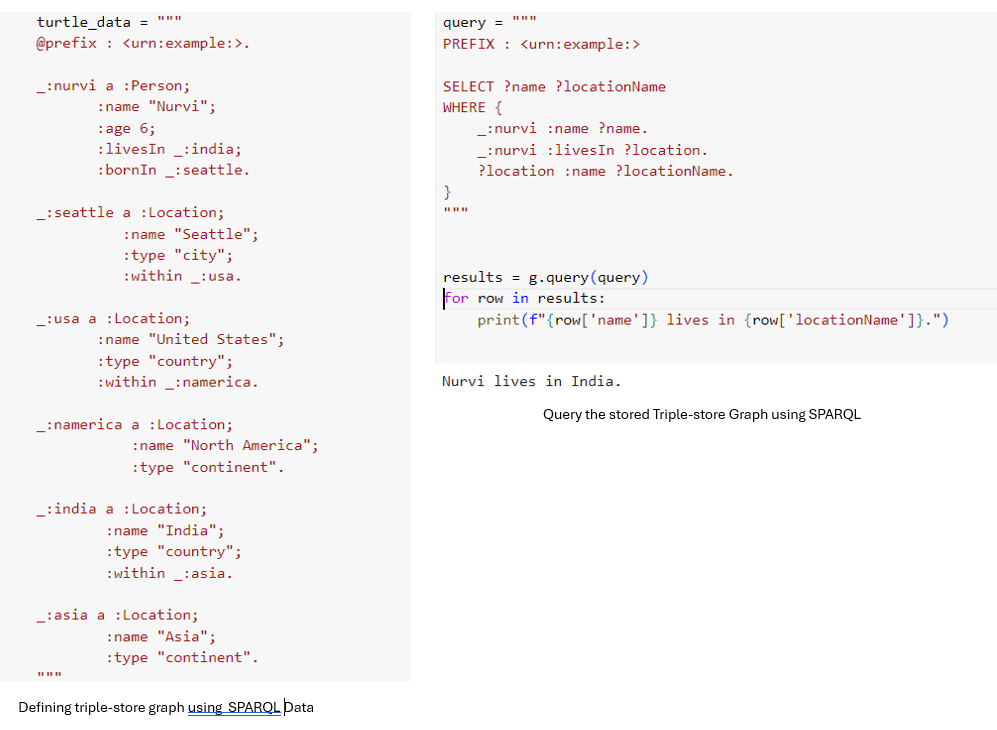
The triple-store model represents data as triples (subject, predicate, object). Implemented by databases such as Datomic and AllegroGraph, This model is commonly used for storing semantic data and supporting RDF (Resource Description Framework).
Example : (Nurvi, Live, India)Subject: Nurvi (the entity being described)
Predicate: Live (the relationship or characteristic)
Object: India(the entity related to the subject)
In a triple-store, the subject of a triple corresponds to a vertex in a graph.
If the object is a primitive datatype (like a string or number), the predicate-object pair acts like a key-value property of the subject vertex (e.g.,
(Nurvi, age, 6)represents Nurvi's vertex with an age property of 6).If the object is another vertex, the predicate represents an edge connecting the subject and object vertices, forming a relationship between them (e.g.,
(Nurvi, Live, India)represents an edge labeled "Lives" connecting two vertices Nurvi, India).Triple-stores use the Resource Description Framework (RDF) to store data as triples (subject, predicate, object), making it structured and ideal for data exchange on the semantic web.
what is Semantic Web ? The semantic web aims to make web data machine-readable, enabling computers to understand and interpret data, forming a global "database of everything.
RDF (Resource Description Framework) was created to allow websites to share data in a standard way, making it possible to combine information from different sites into a unified "web of data.
RDF uses URIs for global uniqueness and can be written in human-readable formats like Turtle, facilitating data merging from different sources.
SPARQL is a query language for RDF data, similar to Cypher, enabling powerful and concise querying of graph-like data. It is valuable for applications requiring complex data interactions.
Below is example of using SparQL to store and retrieve the data.
What is Datalog ?
Datalog is an older query language from the 1980s that serves as a foundation for later query languages like SPARQL and Cypher. It is less known among software engineers but plays a crucial role in querying logic-based data systems.
How is Data Organized in Datalog?
Data in Datalog is organizedsing facts a und rules, similar to the triple-store model. Information is stored in the form of predicates, written as predicate(subject, object)When to Use Datalog?
Datalog is particularly useful when you need to work with complex data relationships and rule-based logic. It's suitable for scenarios where you need to define and reuse complex query logic modularly, making it powerful for reasoning and inferencing tasks.Examples: Prolog, DataScript, Fluree . ItA is commonly used in research, expert systems, artificial intelligence, and databases that require logical rule-based querying capabilities.
Summary :I am linking my Handwritten Notes and Chapter 2 of Designing Data Intensive Application here for your reference. Handwritten Notes for Chapter 2. Thank You.
Thank you for reading. I hope you found the content informative. If you have any questions or feedback, please don't hesitate to leave a comment. Thank you for your attention, and please consider subscribing to stay updated.